p6spy를 사용해서 쿼리 매개변수를 볼 수 있게 설정
3.0.0이상버전을 이용하는 경우, p6spy 1.9.0버전을 이용하면, 마이그래이션이 적용되어있기 때문에
설치만 해도 기본적으로 쿼리는 볼 수 있다.
build.gradle에 아래왜 같이 추가한다.
// https://mvnrepository.com/artifact/com.github.gavlyukovskiy/p6spy-spring-boot-starter
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.9.0'
그 다음, application.yml에 아래와 같은 설정을 추가하면 로그가 보인다.
#p6spy log Setting
decorator:
datasource:
p6spy:
enable-logging: true
하지만 이러면 쿼리가 한 줄로 보기에 좋지않게 나오므로 formatting을 해주는 Config 클래스를 만들어서 설정해주자.
import com.p6spy.engine.logging.Category;
import com.p6spy.engine.spy.P6SpyOptions;
import com.p6spy.engine.spy.appender.MessageFormattingStrategy;
import jakarta.annotation.PostConstruct;
import org.hibernate.engine.jdbc.internal.FormatStyle;
import org.springframework.context.annotation.Configuration;
import java.util.Locale;
@Configuration
public class P6SpyConfig implements MessageFormattingStrategy {
@PostConstruct
public void setLogMessageFormat() {
P6SpyOptions.getActiveInstance().setLogMessageFormat(this.getClass().getName());
}
@Override
public String formatMessage(int connectionId, String now, long elapsed, String category, String prepared, String sql, String url) {
sql = formatSql(category, sql);
return String.format("[%s] | %d ms | %s", category, elapsed, formatSql(category, sql));
}
private String formatSql(String category, String sql) {
if (sql != null && !sql.trim().isEmpty() && Category.STATEMENT.getName().equals(category)) {
String trimmedSQL = sql.trim().toLowerCase(Locale.ROOT);
if (trimmedSQL.startsWith("create") || trimmedSQL.startsWith("alter") || trimmedSQL.startsWith("comment")) {
sql = FormatStyle.DDL.getFormatter().format(sql);
} else {
sql = FormatStyle.BASIC.getFormatter().format(sql);
}
return sql;
}
return sql;
}
}
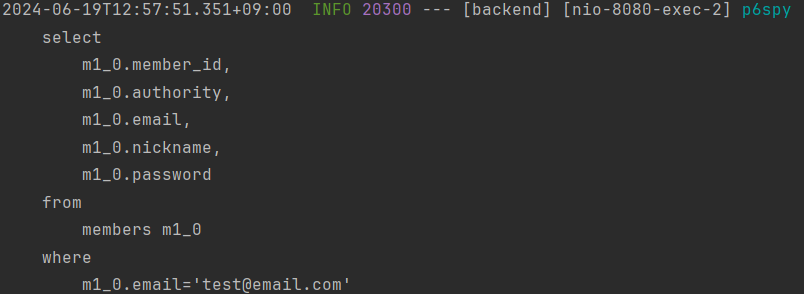
Config 클래스를 추가해주고 서버를 재시작하면 위와 같이 줄바꿈 포맷이 적용되어 깔끔하게 쿼리를 볼 수 있다.
- 참고 블로그
p6spy를 이용한 쿼리 매개변수 로그
https://shanepark.tistory.com/415 위 글을 참조해서 설정했다. 기본적으로 DB쿼리를 볼 수 있게 설정할 때, 아래와 같은 설정을 이용한다. 하지만 위 글대로 설정하면 불편한 점이 있다. 매개변수 따로,
velog.io
Java17에서의 stream의 .collect(Collectors.toList()) -> .toList()
기존 Java에서 stream을 통해 ArrayList를 반환받아야할 경우, .collect(Collectors.toList())를 사용해야 했었다. 하지만 Java16버전부터는 stream에 .toList() 메서드가 추가되었다.
.collect(Collectors.toList())는 ArrayList를 반환하고, .toList() 는 Collectors.UnmodifiableList 또는 Collectors.UnmodifiableRandomAccessList 를 반환한다.
만약 반환받은 리스트를 이후에 수정하게 될 때, .toList()로 반환하면 수정하지 못하고 UnsupportedOperationException가 발생한다.
UnsupportedOperationException는 RuntimeException의 구현체로서 런타임 시점에 알 수 있기에 코드를 실행하기 이전에는 알지 못한다. 그렇기에 IDE 상에서도 위 예제 코드에서 오류를 예측하지 못한다.
- 참고 블로그
Stream.toList로 Stream.collect(toList())를 대체해도 되는 걸까?
최근 JDK 17 release 되었고, JDK 11 다음의 LTS 버전으로서 오랫동안 지원이 되는 만큼 업무/개인프로젝트 등에서 적극적으로 사용하고 있다. Stream.toList() JDK17 기반에서 Stream을 사용해 List로 변환(collec
binux.tistory.com
JPA N + 1 문제 해결
사용자의 카드 주문 목록을 조회하던 중, JPA를 사용했을 때 대표적으로 발생할 수 있는 문제인 N + 1 문제가 발생했다.
N+1 문제란?
연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오는 현상
우선 엔티티의 멤버변수에 @~ToOne의 어노테이션으로 연관관계를 표시하게될 경우, default fetchType이 EAGER로 설정되어있어 예측 못한 쿼리가 발생할 수 있어서 LAZY로 설정하게 된다. (@~ToMany의 경우 default가 LAZY)
이제 엔티티에 대해 조회를 하게 되면 LAZY로 fetchType이 설정된 멤버 객체들은 Proxy객체로 가져오게 된다.
- Proxy의 특징
프록시는 실제 객체를 상속받아 만들어지며, 사용자는 프록시 객체인지 실제 객체인지 구분하지 않고 사용할 수 있다.
프록시 객체는 실제 객체의 참조(target)를 보관하며, 프록시 객체는 실제 객체의 메서드를 호출한다.
이후에 해당 객체에 대한 정보를 찾아서 적용하려고 할 때, 실제 데이터를 불러오기 위해 DB에 쿼리문을 보내게 되고 객체에 여러개의 데이터가 있는 경우, 그만큼 반복하며 DB에 쿼리문을 보내게 되며 N+1 문제가 발생한다.
현재 카드 목록을 조회하는 코드와 관계된 클래스 구조와 메서드는 아래와 같다.

/**
* 유저가 주문한 카드 목록 조회
* @return
*/
@Transactional(readOnly = true)
public CardOrderResponseDto findCardOrders() {
List<CardOrder> cardOrders = cardOrderRepository.findCardOrdersByMemberId(SecurityUtils.getCurrentMemberId());
List<CardOrderDto> result = cardOrders.stream()
.map(o -> new CardOrderDto(o))
.toList();
return new CardOrderResponseDto(result);
}
@Data
public class CardOrderDto {
private Long cardOrderId;
private LocalDateTime orderDate;
private List<CardItemDto> cardItems;
public CardOrderDto(CardOrder cardOrder) {
cardOrderId = cardOrder.getId();
orderDate = cardOrder.getOrderDate();
cardItems = cardOrder.getCardItems().stream()
.map(cardItem -> new CardItemDto(cardItem))
.toList();
}
}
그리고 아래는 memberId가 2인 유저의 카드 주문 조회를 1번 할 때 DB에 전송된 쿼리문이다.
2024-06-19T21:39:23.164+09:00 INFO 26116 --- [backend] [nio-8080-exec-6] p6spy : [statement] | 5 ms |
select
co1_0.card_order_id,
co1_0.member_id,
co1_0.order_date
from
card_orders co1_0
where
co1_0.member_id=2
2024-06-19T21:39:23.200+09:00 INFO 26116 --- [backend] [nio-8080-exec-6] p6spy : [statement] | 2 ms |
select
ci1_0.card_order_id,
ci1_0.card_item_id,
ci1_0.card_id
from
card_items ci1_0
where
ci1_0.card_order_id=1
2024-06-19T21:39:23.215+09:00 INFO 26116 --- [backend] [nio-8080-exec-6] p6spy : [statement] | 3 ms |
select
c1_0.card_id,
c1_0.annual_fee,
c1_0.benefits,
c1_0.image,
c1_0.name,
c1_0.pre_month_performance
from
cards c1_0
where
c1_0.card_id=1
2024-06-19T21:39:23.221+09:00 INFO 26116 --- [backend] [nio-8080-exec-6] p6spy : [statement] | 1 ms |
select
ci1_0.card_order_id,
ci1_0.card_item_id,
ci1_0.card_id
from
card_items ci1_0
where
ci1_0.card_order_id=2
2024-06-19T21:39:23.228+09:00 INFO 26116 --- [backend] [nio-8080-exec-6] p6spy : [statement] | 2 ms |
select
c1_0.card_id,
c1_0.annual_fee,
c1_0.benefits,
c1_0.image,
c1_0.name,
c1_0.pre_month_performance
from
cards c1_0
where
c1_0.card_id=2
2024-06-19T21:39:23.234+09:00 INFO 26116 --- [backend] [nio-8080-exec-6] p6spy : [statement] | 2 ms |
select
c1_0.card_id,
c1_0.annual_fee,
c1_0.benefits,
c1_0.image,
c1_0.name,
c1_0.pre_month_performance
from
cards c1_0
where
c1_0.card_id=3
현재 상황을 정리해보자.
1. memberId에 해당하는 CardOrder 리스트를 조회하고, CardItem 객체는 지연로딩으로 설정했기에 프록시 객체로 생성한다.
2. CardOrderDto로 매핑하기 위해 생성자를 호출할 때, 지연로딩으로 프록시 객체로 생성해뒀던 CardItem 객체를 사용하려고 하는 시점에 영속성 컨텍스트에서 해당 객체가 있는지 확인한다.
3. 영속성 컨텍스트에 찾으려는 CardItem 객체가 없으므로 stream 반복문을 돌 때마다 DB에 CardItem 조회 쿼리를 전송한다.
4. 이어서 CardItem의 cardId에 해당하는 Card 조회 쿼리를 DB에 전송한다.
이제 이 문제를 해결하기 위해서 fetch join을 사용해보자.
fetch join은 JPQL을 사용하여 DB에서 데이터를 가져올 때 처음부터 연관된 데이터까지 같이 join, select하여 가져오게 하는 방법이다.
별도의 메소드를 만들어줘야 하며 @Query 어노테이션을 사용해서 "join fetch 엔티티.연관관계_엔티티" 구문을 만들어 주면 된다.
public interface CardOrderRepository extends JpaRepository<CardOrder, Long> {
@Query("select distinct co from CardOrder co" +
" join fetch co.cardItems ci" +
" join fetch ci.card c")
List<CardOrder> findCardOrdersByMemberId(Long memberId);
}2024-06-19T22:25:51.988+09:00 INFO 23256 --- [backend] [nio-8080-exec-3] p6spy : [statement] | 6 ms |
select
distinct co1_0.card_order_id,
ci1_0.card_order_id,
ci1_0.card_item_id,
c1_0.card_id,
c1_0.annual_fee,
c1_0.benefits,
c1_0.image,
c1_0.name,
c1_0.pre_month_performance,
co1_0.member_id,
co1_0.order_date
from
card_orders co1_0
join
card_items ci1_0
on co1_0.card_order_id=ci1_0.card_order_id
join
cards c1_0
on c1_0.card_id=ci1_0.card_id
이제 fetch join 덕분에 위와 같이 SQL이 1번만 실행된다.
distinct를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가하는데, 그 결과 같은 CardOrder 엔티티의 조회 수도 증가하게 된다.
JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면 애플리케이션에서 중복을 걸러준다.
현재 내 코드의 경우, cardOrder가 컬렉션 fetch join때문에 중복 조회되는 것을 막아준다.
하지만 이 경우 단점이 한가지 있는데, 컬렉션 fetch join을 사용하면 페이징이 불가능하다는 점이다.
여기서 페이징을 하면 하이버네이트는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고 (limit, offset 사용x), 메모리에서 페이징한다. 이렇게 페이징을 수행하는 것은 매우 위험하다.
컬렉션을 fetch join하면 1대다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
1대다에서 1을 기준으로 페이징을 목적으로 하지만, 데이터는 다(N)을 기준으로 행이 생성된다.
현재 내 경우, CardOrder를 기준으로 페이징하고 싶지만 CardItem이 기준이 되버리는 것이다.
이를 해결하기 위해서는 hibernate.default_batch_fetch_size나 @BatchSize를 적용하면된다.
1. 우선 ToOne 관계를 모두 fetch join 해준다. 왜냐하면 ToOne 관계는 행의 개수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다.
2. 컬렉션은 지연 로딩(LAZY)으로 조회한다.
3. 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size나 @BatchSize를 적용한다.
- hibernate.default_batch_fetch_size: 글로벌 설정
- @BatchSize: 개별 최적화
- 이 옵션을 사용하면 컬렉션이나 프록시 객체를 한꺼번에 설정한 size만큼 IN 쿼리로 조회하여 N+1문제를 해결할 수 있다
이제 수정한 코드와 쿼리문, 실행 결과를 보자.
public interface CardOrderRepository extends JpaRepository<CardOrder, Long> {
@Query("select co from CardOrder co")
Page<CardOrder> findCardOrdersByMemberId(Long memberId, Pageable pageable);
}@Transactional(readOnly = true)
public CardOrderResponseDto findCardOrders(int offset, int limit) {
Page<CardOrder> cardOrdersPage = cardOrderRepository.findCardOrdersByMemberId(SecurityUtils.getCurrentMemberId(),
PageRequest.of(offset, limit));
List<CardOrder> cardOrders = cardOrdersPage.getContent();
List<CardOrderDto> result = cardOrders.stream()
.map(o -> new CardOrderDto(o))
.toList();
return new CardOrderResponseDto(result, cardOrdersPage.getTotalElements(), cardOrdersPage.getTotalPages(),
cardOrdersPage.getSize(), cardOrdersPage.getNumber(), cardOrdersPage.isFirst(), cardOrdersPage.isLast());
}2024-06-19T23:09:08.245+09:00 INFO 4912 --- [backend] [nio-8080-exec-3] p6spy : [statement] | 3 ms |
select
co1_0.card_order_id,
co1_0.member_id,
co1_0.order_date
from
card_orders co1_0
limit
0, 2
2024-06-19T23:09:08.294+09:00 INFO 4912 --- [backend] [nio-8080-exec-3] p6spy : [statement] | 3 ms |
select
count(co1_0.card_order_id)
from
card_orders co1_0
2024-06-19T23:09:08.328+09:00 INFO 4912 --- [backend] [nio-8080-exec-3] p6spy : [statement] | 2 ms |
select
ci1_0.card_order_id,
ci1_0.card_item_id,
ci1_0.card_id
from
card_items ci1_0
where
ci1_0.card_order_id in (1, 2, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL)
2024-06-19T23:09:08.351+09:00 INFO 4912 --- [backend] [nio-8080-exec-3] p6spy : [statement] | 2 ms |
select
c1_0.card_id,
c1_0.annual_fee,
c1_0.benefits,
c1_0.image,
c1_0.name,
c1_0.pre_month_performance
from
cards c1_0
where
c1_0.card_id in (1, 2, 3, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL)
// 포스트맨 실행 결과
{
"cardOrders": [
{
"cardOrderId": 1,
"orderDate": "2024-06-18T00:00:00",
"cardItems": [
{
"cardId": 1,
"cardName": "삼성카드 taptap O",
"cardImage": "https://vertical.pstatic.net/vertical-cardad/creatives/SS/1530/SS_1530_20221229-134605_hor.png"
}
]
},
{
"cardOrderId": 2,
"orderDate": "2024-06-19T00:00:00",
"cardItems": [
{
"cardId": 2,
"cardName": "디지로카 London",
"cardImage": "https://vertical.pstatic.net/vertical-cardad/creatives/LO/10304/LO_10304_20231114-020043_ver.png"
},
{
"cardId": 3,
"cardName": "디지로카 Monaco",
"cardImage": "https://vertical.pstatic.net/vertical-cardad/creatives/LO/10305/LO_10305_20231114-025827_ver.png"
}
]
}
],
"totalElements": 3,
"totalPages": 2,
"size": 2,
"number": 0,
"isFirst": true,
"isLast": false
}
이제 페이징이 될 뿐만 아니라 쿼리 호출수가 1+N이 아닌 1+1로 최적화되는 것을 볼 수 있다.
해당 방법의 장점은 아래와 같다
1. 쿼리 호출 수가 1+1로 최적화된다.
2. 조인보다 DB 데이터 전송량이 최적화 된다. (CardOrder와 CardItem을 조인하면 CardOrder가 CardItem만큼 중복해서 조회된다. 하지만 이 방법은 각각 조회하므로 전송해야할 중복 데이터가 없다.
3. fetch join 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 데이터 전송량이 감소한다.
4. 컬렉션 fetch join은 페이징이 불가능하지만 이 방법은 페이징이 가능하다.
결론적으로 ToOne 관계는 fetch join해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 fetch join으로 쿼리 수를 줄여서 해결하고 나머지는 hibernate.default_batch_fetch_size로 최적화하면 좋을 것이다.
마지막으로 hibernate.default_batch_fetch_size의 크기는 100~1000 사이를 선택하는 것이 좋다.
왜냐하면 이 전략은 SQL IN절을 사용하는데, DB에 따라 IN절 파라미터를 1000으로 제한하기도 하기 때문이다.
또한, 1000으로 설정하는 것이 성능상 가장 좋지만 한 번에 1000개를 DB에서 애플리케이션으로 불러오면 애플리케이션은 메모리 사용량이 같지만 DB에는 순간 부하가 증가할 수 있으므로 순간 부하를 견딜 수 있는 만큼으로 결정하면 된다.

댓글