
Set<E> 컬렉션의 특징
Set<E>는 List<E>의 동일한 타입의 묶음이라는 특징은 갖고 있지만 ArrayList<E>처럼 인덱스 정보를 포함하고 있지 않은 집합의 개념과 같은 컬렉션이다.
인덱스 정보가 없으므로 데이터가 중복해서 저장되면 중복된 데이터중 특정 데이터를 꺼낼 방법이 없다. 따라서 동일한 데이터의 중복된 저장을 허용하지 않는다.
Set<E>의 주요 메서드
| 구분 | 리턴 타입 | 메서드명 | 기능 |
| 데이터 추가 | boolean | add(E element) | 매개변수로 입력된 원소를 리스트에 추가 |
| boolean | addAll(Collection<? Extends E> c) | 매개변수로 입력된 컬렉션 전체를 추가 | |
| 데이터 삭제 | boolean | remove(Object o) | 원소 중 매개변수 입력과 동일한 객체 삭제 |
| void | clear() | 전체 원소 삭제 | |
| 데이터 정보 추출 |
boolean | isEmpty() | Set<E> 객체가 비어 있는지 여부를 리턴 |
| boolean | contains(Object o) | 매개변수로 입력된 원소가 있는지 여부를 리턴 | |
| int | size() | 리스트 객체 내에 포함된 원소의 개수 | |
| Iterator<E> | iterator() | 리스트 객체 내의 데이터를 연속해 꺼내는 Iterator 객체 리턴 | |
| Set<E> 객체 배열 변환 |
Object[] | toArray() | 리스트를 Object 배열로 변환 |
| T[] | toArray(T[] t) | 입력매개변수로 전달한 타입의 배열로 변환 |
HashSet<E> 구현 클래스
HashSet<E>는 Set<E> 인터페이스의 대표적인 구현 클래스다.
저장 용량을 동적으로 관리할 수 있고, 저장 데이터를 꺼낼 때는 입력 순서와 다를 수 있다.
또한 HashSet<E>의 데이터 중복 확인은 데이터의 hashcode()가 동일한지와 equal() 결과가 true인지 확인한 후에 둘 다 true라면 같은 데이터로 판단한다.
만약 사용자 정의 클래스를 만든 후에 임의로 동일 데이터 판단 기준을 만들고 싶으면 위의 두 메서드를 오버라이딩하면 된다.
public class HashSetExample {
public static void main(String[] args) {
Set<String> hashSet = new HashSet<>();
Set<String> hashSet2 = new HashSet<>();
// 데이터 추가
hashSet.add("가");
hashSet.add("나");
hashSet.add("다");
hashSet.add("가");
System.out.println(hashSet);
hashSet2.add("라");
hashSet2.add("마");
hashSet.addAll(hashSet2);
System.out.println(hashSet);
// 데이터 삭제
hashSet.remove("가");
System.out.println(hashSet);
// 정보 추출
System.out.println(hashSet.isEmpty());
System.out.println(hashSet.contains("나"));
System.out.println(hashSet.size());
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next() + " ");
}
}
}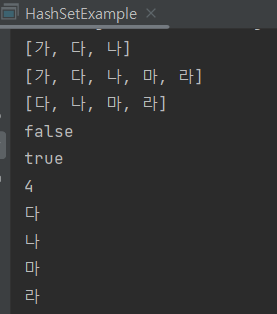
add()를 할 경우 "가"가 두번째로 추가될 때 동일한 데이터이므로 1개만 저장되는 것을 볼 수 있다.
그리고 실행 결과에서 볼 수 있듯이, 데이터가 추가된 순서대로 출력 순서가 보장되지 않는다.
Set<E> 객체에는 index 번호가 없으므로 데이터를 삭제하려면 remove() 메서드의 매개변수에 실제로 삭제할 원솟값을 넣어야한다.
isEmpty() 메서드는 데이터가 비어있는지 여부를 확인할 수 있고, contains() 메서드는 객체 안에 해당 원소가 있는지를 확인할 수 있다.
size()는 저장된 데이터의 개수를 정수형으로 리턴한다.
iterator() 메서드는 Set<E> 객체 내부의 데이터를 1개씩 꺼내서 처리하고자 할 때 사용할 수 있다.
Set<E>는 index 번호가 없으므로 List<E> 객체처럼 일반적인 for문으로 1개씩 데이터를 꺼내는 것은 불가능하다. 따라서 iterator를 사용해 데이터를 꺼내거나 아래와 같이 for-each문을 활용해서 꺼내야 한다.
LinkedHashSet<E> 구현 클래스
HashSet<E>는 하나의 주머니 안에 데이터를 보관하는 개념으로, 입출력 순서는 서로 다를 수 있었다.
LinkedHashSet<E>는 HashSet<E>의 자식 클래스로 HashSet<E>의 모든 기능에 데이터 간의 연결 정보만을 추가로 갖고 있는 컬렉션이다. 즉, 입력된 순서를 기억하고 있다.
따라서 LinkedHashSet<E>는 출력 순서가 항상 입력 순서와 동일한 특징을 갖고 있다.
하지만, List<E>처럼 중간에 데이터를 추가하거나, 특정 순서에 저장된 값을 가져오는 것은 불가능하다.
TreeSet<E> 구현 클래스
TreeSet<E>는 공통적인 Set<E>의 기능에 크기에 따른 정렬, 검색 기능이 추가된 컬렉션이다.
TreeSet<E>는 데이터의 입력 순서와 상관없이 크기순으로 출력한다.
따라서 HashSet<E>에서는 두 객체가 같은지, 다른지를 비교했다면 TreeSet<E>에서는 두 객체의 크기를 비교해야 한다.
TreeSet<E>는 다른 Set<E>의 구현 클래스와 달리 NavigableSet<E>와 SortedSet<E>를 부모 인터페이스로 두고 있다. 이 두 인터페이스에서 TreeSet<E>의 가장 주요한 기능인 정렬과 검색 기능이 추가로 정의됐다.
따라서 TreeSet<E> 생성자로 객체를 생성해도 Set<E> 타입으로 선언하면 추가된 정렬, 검색 기능을 사용할 수 없다. 즉, TreeSet<E>로 선언해야 정렬, 검색 메서드를 호출할 수 있다.
Set<Integer> treeSet1 = new TreeSet<>(); // 정렬, 검색 기능 메서드 사용 불가
TreeSet<Integer> treeSet2 = new TreeSet<>(); // 정렬, 검색 기능 메서드 사용 가능
TreeSet<E>에서 사용자 정의 클래스에 대한 크기 비교를 하고 싶다면 해당 클래스에 대한 크기 비교의 기준을 제공해야한다.
크기 비교의 기준을 제공하는 방법은 2가지다.
첫번째 방법은 java.lang 패키지의 Comparable<T> 제네릭 인터페이스를 구현하는 것이다.
이 인터페이스의 내부에는 정숫값을 리턴하는 int compareTo(T t) 추상 메서드가 존재한다. 해당 메서드에서 크기 비교의 결과는 자신의 객체가 매개변수 t보다 작을 때는 음수, 같을 때는 0, 클 때는 양수를 리턴하면 된다.
class ComparableClass implements Comparable<ComparableClass> {
int data;
public ComparableClass(int data) {
this.data = data;
}
@Override
public int compareTo(ComparableClass o) {
return this.data - o.data;
}
}
두번째 방법은 TreeSet<E> 객체를 생성하면서 생성자 매개변수로 Comparator<T> 객체를 제공하는 것이다.
Comparator<T> 또한 인터페이스이므로 TreeSet<T> 객체 생성 과정에서 내부에 포함된 추상 메서드인 compare()를 구현함으로써 크기 비교의 기준을 갖게 되는 것이다.
이 방법을 사용하면 위의 Comparable 클래스를 Comparable<T> 인터페이스를 구현하면서 수정하지 않아도 된다.
TreeSet<ComparableClass> treeSet = new TreeSet<>(new Comparator<ComparableClass>() {
@Override
public int compare(ComparableClass o1, ComparableClass o2) {
return o1.data - o2.data;
}
});
TreeSet<E>의 주요 메서드
| 구분 | 리턴 타입 | 메서드명 | 기능 |
| 데이터 검색 | E | first() | Set 원소 중 가장 작은 원솟값 리턴 |
| E | last() | Set 원소 중 가장 큰 원솟값 리턴 | |
| E | lower(E element) | 매개변수로 입력된 원소보다 작은, 가장 큰 수 | |
| E | higher(E element) | 매개변수로 입력된 원소보다 큰, 가장 작은 수 | |
| E | floor(E element) | 매개변수로 입력된 원소보다 같거나 작은 가장 큰 수 | |
| E | ceiling(E element) | 매개변수로 입력된 원소보다 같거나 큰 가장 작은 수 | |
| 데이터 꺼내기 | E | pollFirst() | Set 원소들 중 가장 작은 원솟값을 꺼내 리턴 |
| E | pollLast() | Set 원소들 중 가장 큰 원솟값을 꺼내 리턴 | |
| 데이터 부분 집합 생성 |
SortedSet<E> | headSet(E toElement) | toElement 미만인 모든 원소로 구성된 Set을 리턴 |
| NavigableSet<E> | headSet(E toElement, boolean inclusive) | toElement 미만(inclusive=false)/이하(inclusive=true)인 모든 원소로 구성된 Set을 리턴 | |
| SortedSet<E> | tailSet(E fromElement) | fromElement 이상인 모든 원소로 구성된 Set을 리턴 | |
| NavigableSet<E> | tailSet(E fromElemnt, boolean inclusive) | fromElement 초과(inclusive=false)/이상(inclusive=true)인 모든 원소로 구성된 Set을 리턴 | |
| SortedSet<E> | subSet(E fromElement, E toElement) | fromElement 이상 toElement 미만인 원소들로 구성된 Set을 리턴 | |
| NavigableSet<E> | subSet(E fromElement, E boolean fromInclusive, toElement, boolean toInclusive) | fromElement 초과(toInclusive=false)/이상(toInclusive=true)이고 toElement 미만(fromInclusive=false)/이하(fromInclusive=true)인 원소로 구성된 Set을 리턴 | |
| 데이터 정렬 | NavigableSet<E> | descendingSet() | 내림차순의 의미가 아니라 현재 정렬 기준을 반대로 변환 |
Reference
- 자바 완전 정복 | 김동형 지음

댓글